
 DAVID GAUTHIER
DAVID GAUTHIERMicrosoft
David Gauthier is director of data center architecture for Microsoft Global Foundation Services. He is responsible for the technical direction and reliability of the integrated infrastructure architectures of Microsoft’s global data center footprint.
Traditional vs. Cloud-Scale
As people around the world entrust ever-increasing amounts of their digital lives to the cloud, the need for online services to operate continuously— regardless of physical failures—becomes imperative. As my colleague David Bills discussed in the first installment of this series, cloud service providers need to move beyond traditional reliance on complex hardware redundancy schemes and instead focus on developing more intelligent software that can monitor, anticipate, and efficiently manage the failure of physical infrastructures. When service availability is engineered in more resilient software, there is greater opportunity to materially rethink how the physical data center is engineered.
Until 2008, like much of the industry, Microsoft followed a traditional enterprise IT approach to data center design and operation—delivering highly available hardware through multiple levels of redundancy. This allowed software developers to count on that hardware always being available, or as near as such that active redundant copies of data were only thought of as disaster recovery. By relying on hardware availability, we enabled the development of brittle software. While we had our fair share of hardware failures and human errors under this early model, we still successfully delivered highly available services. However, as we grew significantly to what we term cloud-scale, we quickly saw that the level of investment and complexity required to stay this course was quickly going to be untenable. We also recognized that brittle software could cause much more significant outages than hardware.
Compile Code, Compile Availability
The cloud-scale data centers we operate today still require a lot of hardware, but software has become the key driver of service availability. In some cases, it significantly reduces the need for physical redundancy. By solving the availability equation in software, we can look at every aspect of the physical environment—from the central processing unit (CPU) to the building itself — as a systems integration and optimization exercise. Through software development tools and workload placement engines, we can ‘compile’ a data center availability solution much faster than we can install physically redundant hardware. This shifting of mindset rapidly creates compounding improvements in reliability, scalability, efficiency, and sustainability across our cloud portfolio.
In our data centers, we have embraced the fact that no amount of money will abate hardware failures or human errors. As such service availability must be engineered at the software layer. No matter what happens, the application or service should gracefully fail over to another cluster or data center while maintaining the customer’s experience. These failures are anticipated as regular operating conditions for the service and are not a reason to wake up the CIO at 2 am.
This approach has led us to accept measured risks in our environment and to delete significant portions of our redundant infrastructure. We are running elevated supply temperatures and have foregone chillers in all but one of our facilities since 2009, resulting in a tremendous reduction of water usage (averaging 1 percent of what traditional data centers use) and significant energy savings (averaging a 50 percent savings). We have also been operating tens of thousands of servers without backup generators since 2009 with no impact to user experience even though outages have occurred. By optimizing the size of our application clusters against uncorrelated failure domains in the physical world, we’ve implemented a fail-small topology that allows us to compartmentalize failure and maintenance impacts.
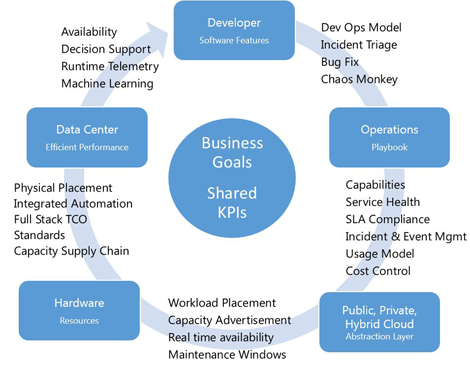
Every GPS Needs a Map
Resilient software solves problems beyond the physical world, but to get there, that software needs to have an intimate understanding of the physical environment it resides on top of. While the role of a data center manager might come with a satellite phone, it rarely comes with a GPS. Very few data center operators have a comprehensive view of how server or workload placements affect service availability. Typical placement activities are more art than science - balancing capacity constraints, utilization targets, virtualization initiatives, and budgets. Relying on hardware takes a variable off the table in this complex dance. But there are a few things you can do to start building the maps and turn-by-turn directions that will enable resilient software in your environment, whether you prefer private, hybrid or public cloud.
- Map physical environment and availability domains: From a hardware standpoint, it’s important to look at the physical placement of hardware against infrastructure. We automate and then integrate that automation to be able to communicate between the data center, the network, the server, and the operations team running them. Understanding the failure and maintenance domains of your data center, server, network, and manageability infrastructure is key to placing virtualized workloads for high availability. Trace the single line diagram to identify common failure points and place software replication pairs in uncorrelated environments. In most data centers, you're limited to one or a handful of failure domains at best. However, with a cloud services’ application platform like Windows Azure, a developer or IT professional can now choose from many different regions and availability domains to spread their applications across many physical hardware environments.
- Define hardware abstractions: As you are looking at private, public, and hybrid cloud solutions, now is a good time to start thinking about how you present the abstraction layer of your data center infrastructure. How workloads are placed on top of data center, server, and network infrastructure can make a significant difference in service resiliency and availability. Rather than assign physical hardware to a workload, can you challenge your systems integrator or software developer to consume compute, storage, and bandwidth resources tied to an availability domain and network latency envelope? In a hardware-abstracted environment, there is a lot room for the data center to become an active participant in the real-time availability decisions made in software. Resilient software solves for problems beyond the physical world. But to get there, the development of this software requires an intimate understanding of the physical infrastructure in order to abstract it away.
- Total cost of operations (TCO) performance and availability metrics: Measure constantly and focus on TCO-driven metrics like performance/dollar/per kW-month, and balance that against revenue, risk, and profit. At cloud-scale, each software revision cycle is an opportunity to improve the infrastructure. The tools available to software developers—whether it be debuggers or coding environments—allow them to understand failures much more rapidly than we can model in the data center space. Enabling shared key performance indicators (KPIs) across the business, developer, IT operations, and data center is key to demonstrating the value of infrastructure to the businesses bottom line. Finally, building bi-directional service contracts with software and business teams will enable these key business, service, and application insights to be holistically leveraged on your journey to the cloud.
Resilient software is a key enabler of service availability in today’s complex IT landscape when operating at cloud-scale. By shifting the mindset away from hardware redundancy, Microsoft has made significant gains in service reliability (uptime), while lowering costs and increasing scalability, efficiency, and sustainability. So while we continue to deliver mission critical services to more than one billion people, 20 million business and in 76 market places around the world, we’re doing it on significantly more resilient, highly-integrated software that is delivered via hardware that is decidedly less than mission critical.
This is the second in a series from Microsoft Global Foundation Services' team. See the first installment and second installment for more.
Industry Perspectives is a content channel at Data Center Knowledge highlighting thought leadership in the data center arena. See our guidelines and submission process for information on participating. View previously published Industry Perspectives in our Knowledge Library.



