

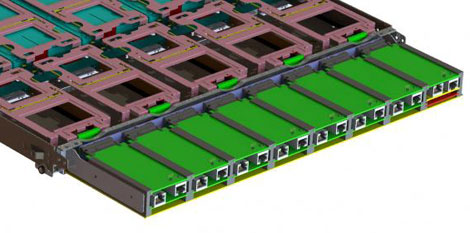
An Adaptive Storage Base Board, which provides an Open Compute-compatible solution for a new approach to optimizing Hadoop clusters. (Image: Open Compute Project)
SAN JOSE, Calif. - Could an overnight Hackathon improve the way Hadoop clusters are optimized for crunching Big Data? January's Open Compute Summit led to the creation of a new concept known as Adaptive Storage, in which compute and storage resources would be loosely coupled over a network and scale independently to optimize big data platforms.
Adaptive Storage was one of the winners in the Open Compute Hackathon, a 24-hour hardware innovation contest. It was developed by a team that included engineers from Facebook, Adapteva, I/O Switch Technologies and several consultants.
"Adaptive Storage raises fundamental questions about the way storage and compute are connected and about the power requirements for big data," team member Ron Herardian reports on the Open Compute blog. "In just 24 hours, with no budget and with a few boxes of computers, circuit boards and networking equipment, our small team of engineers was able to imagine a totally new way of organizing Hadoop data nodes, build and demonstrate a working prototype running on ARM processor-based micro servers using open source software, and show production-ready engineering CAD drawings for a production implementation."
Hadoop is a software framework that supports data-intensive distributed applications. It has become one of the most important technologies for managing large volumes of data, and has given rise to a growing ecosystem of tools and applications that can store and analyze large datasets on commodity hardware.
In adaptive storage, disk drives are connected directly to network switches, with no conventional storage array. Also connected to the switch are Parallella micro servers running Hadoop, each of which can handle data for one or more disk drives. Because every disk drive is individually connected to a network, any micro server can read from any disk drive, allowing the micro servers to join forces to process complex jobs or larger data sets.
"In addition to dramatic power savings and independent, elastic scaling of compute and storage resources, Adaptive Storage is a simple and elegant way to eliminate compute hotspots and coldspots in Hadoop," Herardian writes. "But the concepts and methods of Adaptive Storage are not limited to Hadoop. It can be applied to virtually any big data technology, such as Cassandra or MongoDB or to object storage in general."
For more details, check out the blog post at the Open Compute web site.



