
Cortney Thompson is VP of Data Center Operations, Green House Data.

CORTNEY THOMPSON
Green House Data
In 2004, a conservative Gartner study pegged the average hourly cost of downtime at $42,000 an hour, and by 2012, Aberdeen had increased this estimate to between $98,000 and $138,000 an hour. While the precise impact and real costs of downtime will vary from company to company, recent extreme weather events have pushed many organizations to think more urgently about business continuity planning (BCP).
Application Importance Levels & Cost of Downtime
Using a market approach, the implications of downtime can be understood through application importance levels: mission-critical, business-critical, and best-efforts. If mission-critical applications go down no revenue is generated, service level agreements (SLAs) are broken, and loss in customer base is almost guaranteed. Losing business-critical applications can mean dips in employee productivity, shaken customer confidence, and possibly lost revenue. A loss of best-effort applications reduces efficiency, but otherwise should not negatively impact the ability to do business. Understanding the cost of downtime is the entry point to the disaster recovery (DR) equation. It also clarifies which options provide the best return on investment (ROI) and what dollar amount should be budgeted—yes, budgeted—for DR and business continuity.
Spanning from basic file backup to a total restore, the lower costs and higher resiliency of cloud infrastructure have re-framed disaster recovery discussions by providing greater options for geographic diversity, increased redundancy, and accelerated recovery time objectives (RTO).
Yet, despite multiple technology options, without a defined RTO policy, even the best IT organizations may struggle to prioritize which systems are the most critical during a disaster. Business stakeholders must work alongside IT to define—in advance—clear, time-based objectives for getting back online quickly should an event occur. In addition to providing direction, designing RTO policy will give IT the opportunity to identify any barriers to RTO targets, before the organization has to find out the hard way.
Differences in the Cloud
In a virtualized environment, for example, “snapshots” can offer bare metal restoration extremely quickly, while improvements to backup technology (like the ability to examine data sets in variable segment widths and change block tracking) have enabled the handling of large and complex data and systems in compressed timeframes. When virtualization is paired with physical separation, organizations may be better prepared to meet their RTO through infrastructure redundancy and failover. But, even with the more sophisticated backup and disaster recovery policies developed in the last decade, RTO still remains largely unmapped outside of planned migrations and maintenance windows.
Similarly, the recovery point objective (RPO) helps determine how much information, from a few moments ago to legacy, must be recovered and restored. As data becomes both larger and more valuable as the result of being better quantifiable, the RPO window will only continue to widen in both directions—more historical data will be considered important enough to include in RPO policy, and the initial RPO point will continue to nudge closer and closer to the disaster event.
Cloud infrastructure can also provide the ability to tune the recovery service level (RSL). RSL is a percentage measurement (0-100%) of how much computing power is necessary based on the percentage of the production system needed during a disaster. For example, if a large call center collecting call statistics were to be flooded, only a fraction of the production capability would be needed. Yet, if a large financial institution were to experience the same disaster, full production capability would be required to re-point end-users to a separate geographic location and minimize end-user impact during repairs. From a financial standpoint these two options are wildly different.
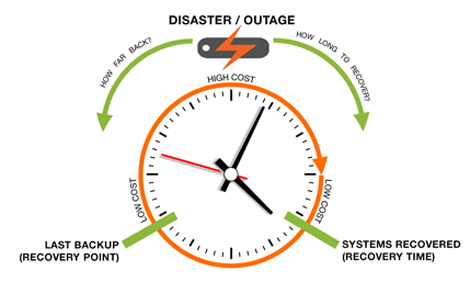
Too often, when working to define BCP objectives, data center service providers hear that clients want instant recovery and zero lost data. Albeit unrealistic from a technical standpoint this is an achievable goal, and both RTO and RPO will significantly influence infrastructure, replication, and backup policy especially frequency. Yet, business objectives must be balanced against cost, which has a parabolic increase as the required RTO and RPO decrease.
What's Your True Recovery Service Level?
One approach in managing these competing priorities lies in examining RSLs. For example, in a disaster, does a department of 10 people need everyone to keep running? Could 5 people sustain a higher response time to the client? Similarly, could a small email server with empty mailboxes restore enough communication to get by, with access to older messages returned once the primary resources are back on-line? Running with a subset of production capacity during a disaster can be a very viable way of aligning BCP objectives to sustainable operating expenditures.
Data centers and data center services providers will likely find their roles shifting to be increasingly hands-on. In a recent Forrester Research report, Senior Analyst Rachel Dines wrote that “more than two-thirds of IT professionals are either actively adopting or at least interested in implementing cloud-based Recovery-as-a-Service (RaaS).”
It seems that ultimately, even pure infrastructure players will feel pressure to offer Recovery -, Backup-, and DR- as-a-Service to help their clients mitigate risks and address the necessity of uptime, even in disaster situations. Today, cloud-based DR is poised to shake up legacy approaches and offer frustrated infrastructure and operations professionals a great alternative. Cloud computing and its pay-as-you-go pricing model allows the enterprise to secure long-term data storage while only paying for servers if they have a need to spin them up for testing or in the event of a disaster. This provides significant cost reduction and removes several barriers to entry for many organizations looking to solidify their BCP.
Finally, organizations must weigh the expectations of the always-on enterprise against practical considerations, and leveraging cloud infrastructure is one way to help strike a balance. They must also be proactive about improving their RTO and RPO policies by asking if they have some systems that are not currently virtualized that could be, if re-examining RSLs would be beneficial, or if they could be using cost-effective public and hybrid clouds to shoulder some of the load.
Industry Perspectives is a content channel at Data Center Knowledge highlighting thought leadership in the data center arena. See our guidelines and submission process for information on participating. View previously published Industry Perspectives in our Knowledge Library.



